I've done all three on some level in my travels, but in the past it's
also been oftentimes vendor-centric which hindered a scalable or
"templateable" solution. (Some things police in only one direction, or
only well in one direction, etc.)
I may misunderstand something here, but are you looking for vendor
agnostic solutions to replace your vendor specific one? That is an
unrealistic goal and it's not clear to me why it would be important
what spell incantation is needed at any given moment.
If you need just to 'rate-limit', and you don't need to discriminate
traffic in any way, it's ezpz🍋sqz. Only thing you need to consider is
your stepdown, is ingress rate higher than egress rate? If you have
speed stepdown, then you need to consider at which RTT rate do I
guarantee full rate on a single TCP session. If you police, you need
to allow a burst rate which can take in the TCP window growth, if you
use a shaper you need to configure buffers which can ingest it.
Consider sender is 10Gbps and RTT is 100ms, and receiver is 1Gbps. The
window the sender may burst is 9Gbps*100ms/2 = 56.25MB. If sender is
100ms, you contractually don't guarantee the customer full rate on a
single TCP session, you point the ticket to a product definition and
close it.
Now if you need to discriminate, things can get very complex.
Particularly if you do QoS at the L3 aggregation at the L2 access
physical rate, you need to understand very well what is the policer
counting L1, L2, L3 rate? And how to get it to count L1 rate. Ideally
you'd do all QoS at the congestion point at ANET, and not on the
subinterfaces. But often the access device is too dumb to do the QoS
you need.
Let's take the complex example, you need to discriminate and do all in
CSCO and ANET does just BE and is QoS unaware. We have a 10GE
interface in CSCO and a customer is 1GE connected at ANET.
Configuration would be something like this:
interface TenGigE0/1/2/3/4.100
service-policy output CUST:XYZ:PARENT account user-defined 28
encapsulation dot1q 100
!
policy-map CUST:XYZ:PARENT
class class-default
service-policy CUST:XYZ:CHILD
shape average 1 gbps
!
end-policy-map
!
RP/0/RSP1/CPU0:r15.labxtx01.us.bb#show run policy-map CUST:XYZ:CHILD
policy-map CUST:XYZ:CHILD
class NC
bandwidth percent 1
!
class AF
bandwidth percent 20
!
class BE
bandwidth percent 78
!
class LE
bandwidth percent 1
!
class class-default
!
end-policy-map
!
Homework:
- what RED curve to use
- how much should you buffer in given class at worst (in some cases
burst cannot be configured small enough, and you need to offer
lower-than-bought rate to be able to honor QoS contract)
- what is right shaper burst
- what to map to each class and how (tip: classify exclusively on
ingress interface by set qos-group, on egress class match exclusively
on the qos-group, this methodology translates across platforms)
If your 'account user-defined' is wrong even by a byte, your
in-contract traffic will be dropped by ANET, because CSCO is admitting
1Gbps ethL1 rate, and ANET is QoS-unaware so will drop LE just in the
same probability as AF.
Further complication, let's assume you are all-tomahawk on ASR9k.
Let's assume TenGigE0/1/2/3/4 as a whole is pushing 6Gbps traffic
across all VLAN, everything is in-contract, nothing is being dropped
for any VLAN in any class. Now VLAN 200 gets DDoS attack of 20Gbps
coming from single backbone interface. I.e. we are offering that
tengig interftace 26Gbps of traffic. What will happen is, all VLANs
start dropping packets QoS unaware, 12.5Gbps is being dropped by the
ingress NPU which is not aware to which VLAN traffic is going nor is
it aware of the QoS policy on the egress VLAN. So VLAN100 starts to
see NC, AF, BE, LE drops, even though the offered rate in VLAN100
remains in-contract in all classes.
To mitigate this to a degree on the backbone side of the ASR9k you
need to set VoQ priority, you have 3 priorities. You could choose for
example BE P2, NC+AF P1 and LE Pdefault. Then if the attack traffic to
VLAN200 is recognised and classified as LE, then we will only see
VLAN0100 LE dropping (as well as every other VLAN LE) instead of all
the classes.
To wish that this would a vendor agnostic is just not realistic, as
there are very specific platform decisions which impact on your QoS
design.
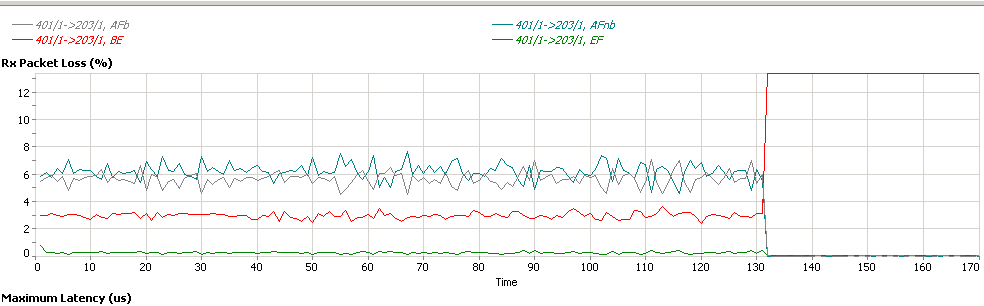
To stress how critical the accounting is, if you do QoS in the 'wrong'
place: https://ytti.fi/after.png
In this picture BE is out of contract, AFnb, AFb and EF are all
in-contract. However the customer sees loss in all classes, this is
because the L3 is shaping at L2 rate not L1 rate, so it's sending
1Gbps to the customer, which is physically limited to 1Gbps, forcing
the QoS-unaware access device to drop. Only thing fixed at 130 is
correct accounting parameter, which causes the L3 to reduce the rate
it can send and causes it to start dropping, and as it is QoS aware,
it can honor the contract, so all drops move to the out-of-contract
class, BE.

{kind=link}